Webhook Anti-patterns Build webhook systems your customers hate
Webhooks are important in modern web architectures, and are a fantastic alternative to costly polling, webhooks, or server-sent events. They allow your application (the producer) to notify another application (the consumer) when an event occurs.
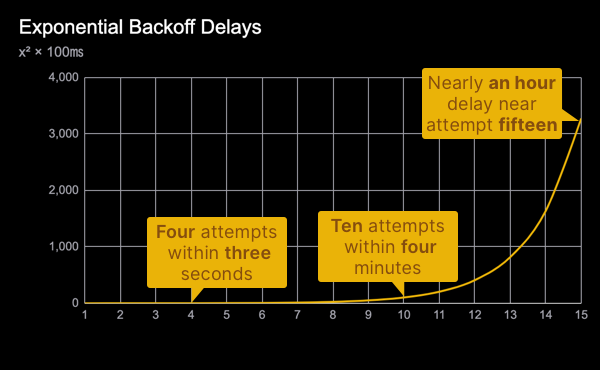
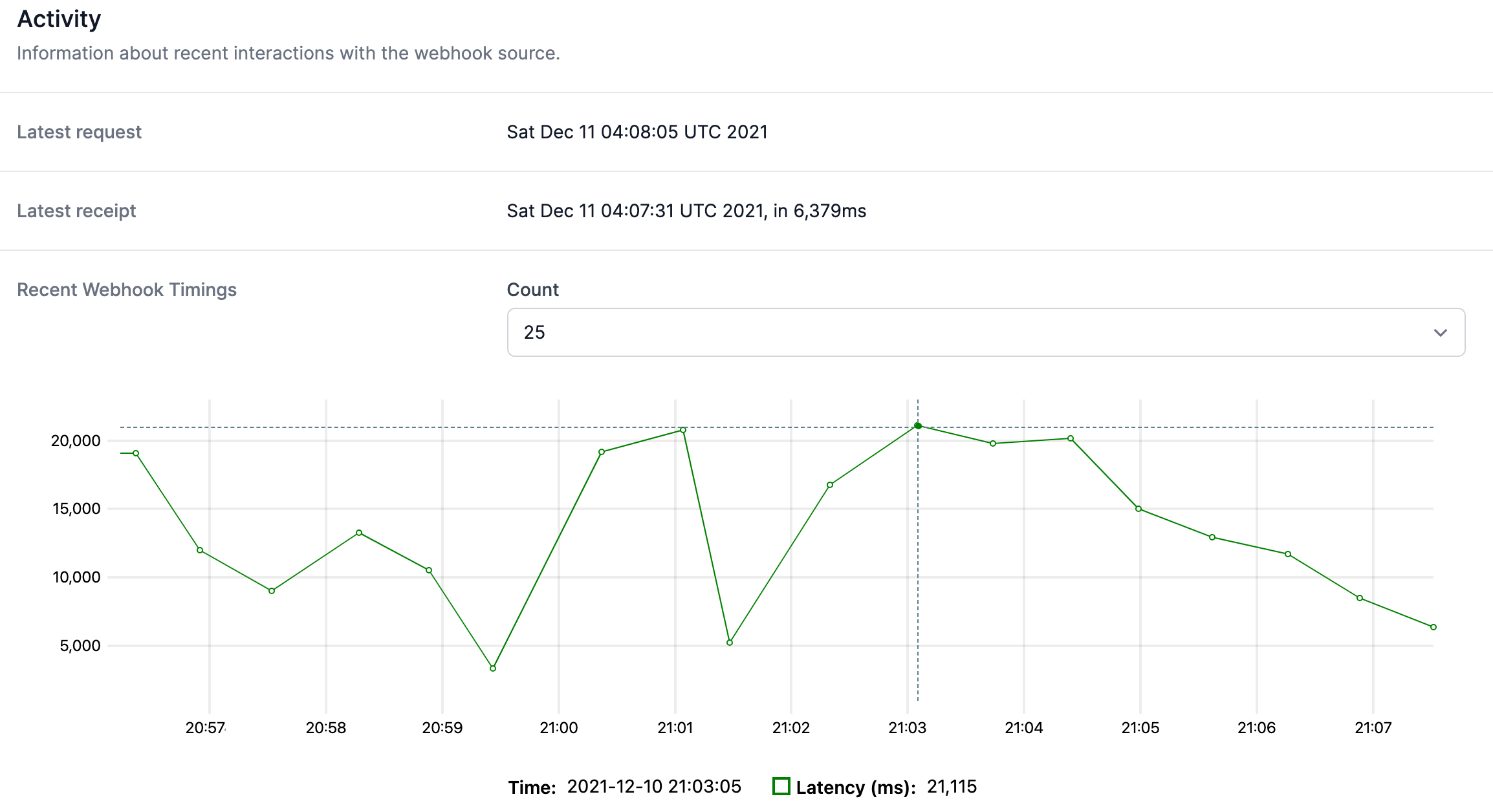
Unfortunately, there are some pitfalls that teams run into when aiming to build world-class systems like they see deployed by companies like Stripe and Shopify. It’s important to explore these in order to avoid building a flawed (or even insecure) system.